Let’s start with an honest admission: Claude and Codex/ChatGPT are good at coding. For many tasks, they are faster and more capable than any open-source model available today.
If you are a student working on homework, a hobbyist building a side project, or a startup with no proprietary code worth protecting, stop reading. Use Antrophic Claude or OpenAI ChatGPT. It will serve you well.
This article is for everyone else.
The convenience problem
Developers love AI coding assistants and coding agents. They speed up refactoring, help debug obscure errors, explain unfamiliar code, and generate boilerplate that nobody wants to write by hand.
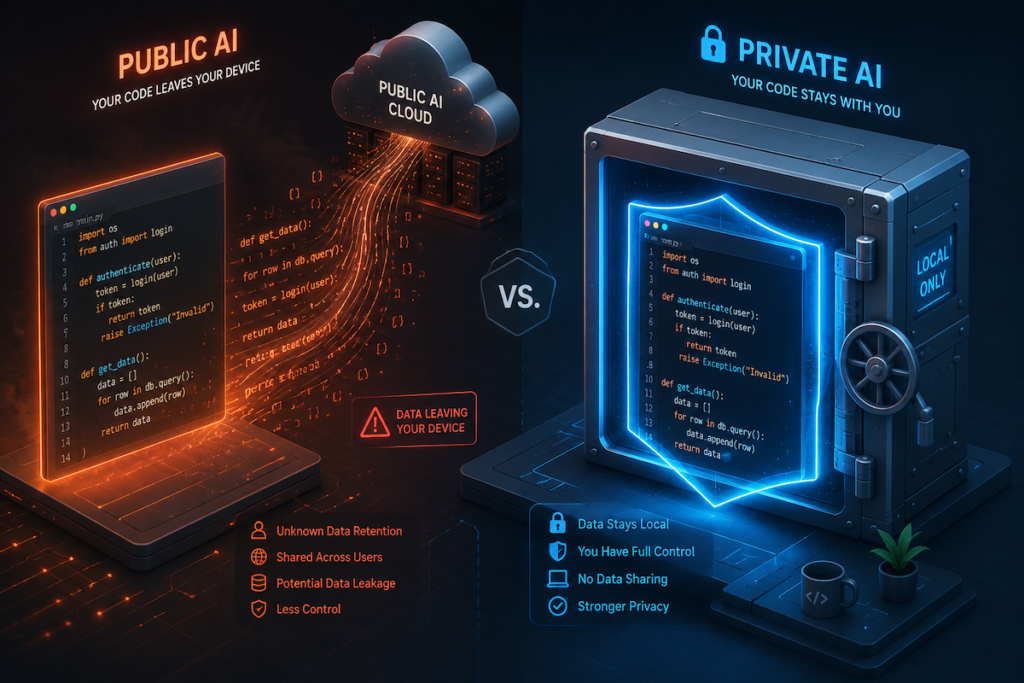
The problem is not the capability. The problem is what happens to your code after you paste it.
When you send proprietary source code, client repositories, internal architecture documents, or confidential business logic through ChatGPT, Claude, Gemini, or Grok, that data enters systems owned by companies whose business model depends on absorbing information.
The incentive problem (not the privacy policy problem)
Most discussions about AI code privacy focus on terms of service and privacy policies. This is the wrong frame.
Privacy policies say “we do not train on your data.” Incentive structures say “we have every reason to train on your data.”
Closed-source AI companies have one critical competitive moat: training data for their next model. Every interaction you have with their product makes that model better. The incentive to log, retain, and learn from your code is not malicious. It is structural. It is how their business works.
Consider the difference:
- ChatGPT, Claude, Gemini, Grok: Their next model needs to be better than their current model. Your proprietary code, your internal architecture, your client logic — all of this is training data. The incentive to log is built into their revenue model.
- Open-source models on rented GPUs: Nobody owns the model exclusively. The GPU provider sells compute by the hour. They have no proprietary model to train. Your code is not their product. The incentive to log is absent.
Policies change with a terms-of-service update. Incentives endure.
When Claude and ChatGPT is fine
Public AI tools are appropriate when:
- You are working on open-source code anyone can see
- You are learning a new framework and asking general questions
- You are prototyping an idea with no business value yet
- Your company has no proprietary code, client confidentiality, or IP constraints
- You are generating marketing copy, documentation for public projects, or non-sensitive content
If none of your code would cause harm if it appeared in a competitor’s hands, a closed source public AI provider is the convenient choice.
When private AI is necessary
Private AI coding assistants are necessary when:
- Your source code is proprietary and core to your business
- You handle client code under NDA or confidentiality agreements
- Your industry has regulatory requirements for data handling (fintech, legaltech, healthtech)
- Your internal architecture represents competitive advantage
- Your developers are working on legacy systems with undocumented business logic
- Your client contracts forbid sending code to third-party AI services
If any of these apply, the convenience of ChatGPT is not worth the risk. Not because OpenAI is evil. Because their incentive structure makes logging rational, and your incentive structure makes protecting your code necessary.
What private AI coding actually looks like
A private AI coding agent/assistant is not a research project. It is a practical installation with clear components:
1. Local developer tool
Your developers use OpenCode on their laptop. The interface is familiar. The workflow does not change.
2. Private mesh network
Requests travel over a private network (Tailscale). No public HTTP exposure. The model endpoint is not accessible from the open internet.
3. Customer-controlled GPU infrastructure
The model runs on your own server or a rented GPU pod under your account. You control the infrastructure. The GPU provider sells compute, not models.
4. Open-source coding model
Models like Qwen 3.6 27B process your code. Nobody owns these models exclusively. There is no proprietary training pipeline on the other end.
5. Private codebase indexing
Your proprietary code and documentation are indexed privately. The assistant searches your actual codebase before answering, instead of guessing from generic training data.
6. Redacted web search
When developers need current public information, search goes through a controlled path with redaction rules. Private code stays private. Public information comes through safely.
The honest quality comparison
Public frontier models (GPT-5, Claude Opus) are still stronger for some tasks. This is true. A private AI setup running Qwen 3.6 27B will not match Claude on every query.
The value is not “better than ChatGPT.” The value is:
- Private code handling: Your source code does not flow through systems owned by companies that sell AI
- Open-source model choice: You pick the model, change it when better ones release, and control the context settings
- Customer-controlled infrastructure: You own or rent the GPU, you control the network, you decide what gets indexed
- Workflow tuning: The assistant is tuned around your codebase and documentation, not generic training data
For many coding tasks — understanding legacy code, searching across a private codebase, generating code that follows your internal patterns — a well-configured private setup is highly useful. For others, it is not yet as strong as the best public models.
The question is whether the quality gap is worth sending your proprietary code to companies whose business model depends on absorbing it.
Three deployment options
Option 1: Customer-controlled GPU pod
You rent a GPU pod under your own account (e.g., RunPod). We install the private AI route, private network path, and codebase search workflow. You control the infrastructure account.
Best for: fast setup, startup and SaaS teams, agencies without existing GPU servers.
Option 2: Your own server
We install the private AI coding assistant inside your server environment. You own the hardware or VM.
Best for: stronger privacy requirements, regulated industries, teams with existing infrastructure.
Option 3: Readiness audit first
For EUR 750, we review your code, privacy, and workflow requirements and produce the exact installation plan. If you proceed within 14 days, the audit fee is credited toward the full installation.
Best for: teams that are interested but not ready to commit to installation yet.
What a starter installation includes
Private AI Coding Assistant Starter Installation — from EUR 2,000
- One bounded codebase or repository group
- Private model route through customer-controlled infrastructure
- One private codebase and one documentation index
- Local developer assistant (OpenCode) with private network connection
- Redacted web-search path
- Developer handover session and operating notes
Timeline: 5–7 working days after access is confirmed.
No production credentials required. Read-only code access by default or upload by yourself. NDA available.
Who this is for
- Small software companies with 1–10 developers and proprietary code
- Technical agencies handling confidential client repositories
- SaaS companies where source code is a competitive asset
- Teams using legacy stacks where generic AI models are weak
- Founders and CTOs who have already questioned whether public AI tools are safe for their codebase
Who this is not for
- Teams comfortable sending all code to public AI providers
- Companies with no developers
- Buyers expecting a perfect Claude/GPT replacement on day one
- Organizations that need enterprise procurement cycles
The bottom line
Claude/ChatGPT is convenient. Private AI is necessary when your code cannot leave the building.
The choice is not about which AI is smarter. It is about understanding who benefits from your data and choosing a path where the incentives align with your interests.
Closed-source providers log because training data is their competitive moat. Open-source models on customer-controlled infrastructure have no logging incentive. The GPU provider sells compute. The model is already open. Your code stays yours.
If your team needs AI coding help but your code, client contracts, or IP policy make public AI tools unacceptable, the next step is a 20-minute fit call.