

The problem
Centralized Datacenter AI providers are powerful. Private source code and company know-how is valuable.
Developers and entrepreneurs want agentic AI coding — not just autocomplete, but an autonomous agent that can refactor, debug, document, and navigate codebases on their behalf. But many teams cannot share proprietary repositories, client code, internal documentation, or architecture details with closed-source AI providers such as OpenAI, Anthropic, or xAI. These providers have a structural incentive to log every interaction: your conversations are training data for their next model.
The alternative is local-only AI. That eliminates the data exposure, but local hardware cannot run strong open-source coding models well enough for serious agentic work.
Our Solution
Local workflow. Private Tailscale network. Scalable Rented GPU power. Strong Open Source Coding Model.
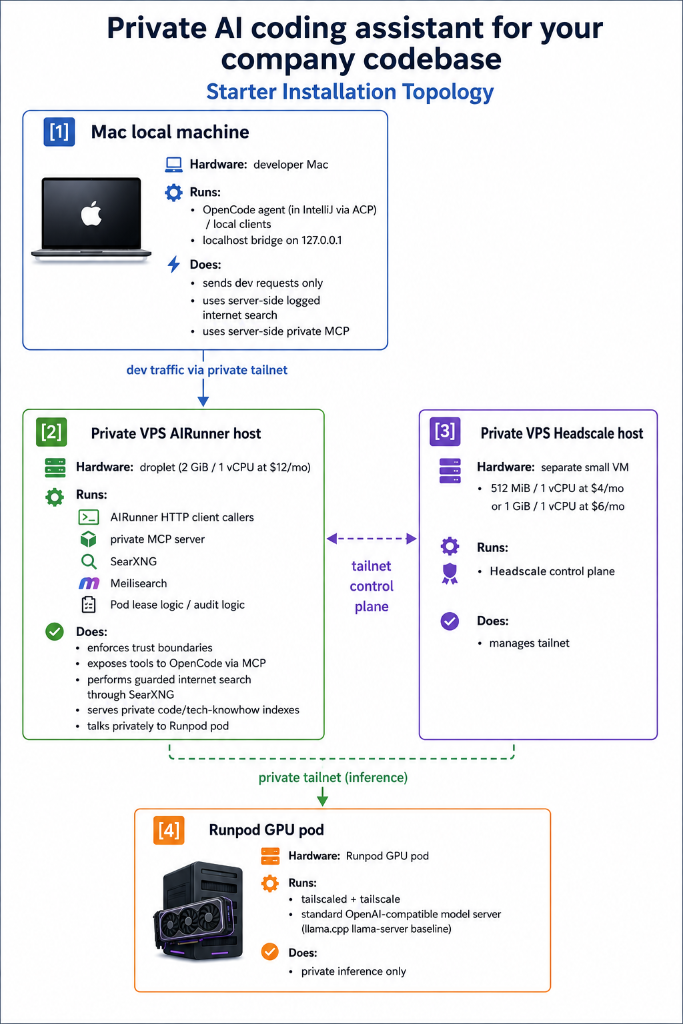
We install your private AI coding assistant path where the developer works locally, the connection travels over a private “next level VPN” Tailscale network, and the heavy model runs on customer-controlled GPU infrastructure.
The result is a practical middle path: strong open-source models such as Alibaba Qwen 3.6 27B most laptops cannot run, without opening your source code and internal company know-how to commercial AI providers.
How the setup works
Secure and private
from Developer Laptop
to GPU
→ local coding assistant (e.g. OpenCode via ACP in IntelliJ)
→ OpenAI compatible local bridge (performant Go client)
→ private mesh network (Headscale/Tailscale)
→ customer-controlled AI gateway (on your private VPS Server)
→ private GPU pod or customer GPU server (i.e Nvidia GeForce RTX 4090)
→ strong open-source coding model (i.e. Qwen 3.6 27b)
Private search indexes for the coding assistant
→ proprietary source-code search
→ confidential company documentation search
→ technical-library documentation search
→ redacted web search
Running on OpenSource software inside Tailscale on your private AI gateway, available via MCP to your OpenCode agent
Your developers use a local coding assistant. The model does not need to run on their laptop or PC. Instead, requests travel over a private network to your controlled AI gateway and then to a GPU machine that runs the selected open-source model. All inside your private Tailscale network with private IPs.
The GPU can be your own server or a rented GPU pod, that can be started and stopped on demand. The rented GPU gives better model power and flexibility than most local machines, while the private network keeps the model endpoint away from public HTTP exposure (not even Cloudflare can see the traffic).
Your company docs and proprietary source code are indexed ("private RAG") and available to your developer's laptops via private MCP.The advantages
Why not only run the model on a laptop/PC?
Local-only models are attractive for privacy, but laptop hardware usually limits model size, speed, context length, and quality.
A private GPU route lets your team run stronger open-source models, scale power up or down, and change model choices over time, while keeping the developer workflow local.
- Better model size options than most developer laptops
- More adaptable GPU power for large codebases
- No need to buy hardware before proving value
- Model can be changed as open-source releases improve
- Endpoint can stay inside a private network instead of public internet exposure
Use strong open-source coding models without public AI uploads
The setup can run open-source models chosen for your budget, GPU size, and workflow. A model such as Qwen 3.6 27B can be a strong private-coding candidate when matched with suitable GPU capacity and context settings.
Public frontier models may still be stronger for some tasks. The value here is control: private code handling, open-source model choice, customer-controlled infrastructure, and the ability to tune the workflow around your codebase and documentation.
Your codebase and technical docs become searchable context
Large language models are not trained on your private source code, and they may be weak on niche frameworks, internal architecture, or proprietary libraries.
We add a private retrieval layer for your repository, project docs, and selected technical documentation. That lets the assistant search relevant code and docs before answering, instead of guessing from generic training data.
- Source-code search for classes, functions, configs, and error messages
- Private project documentation search
- Indexed framework/library docs for less-common stacks
- Bounded snippets instead of full-repository prompt dumping
- Separation between customer code indexes and public/technical docs
Web search with redaction controls
When developers need current public information, the setup can route search through a controlled search path with redaction rules. The goal is to let the assistant look up public technical information without casually leaking private code or secrets into search queries.
Our Offer
Starter Installation from EUR 2,000
A fixed-scope installation for software teams that want AI coding help without public source-code uploads.
Who it is for
- Your developers want agentic AI coding support
- Your source code or client code is confidential
- Public AI providers are not acceptable for full repository context or private company know-how
- Local-only models are too weak or slow
- You want open-source model control
- You need a practical first installation, not a research project
What we install
- Local coding-assistant connection path
- Private AI gateway
- Private mesh network route
- Open-source model running on customer-approved GPU infrastructure
- One private source-codebase, one documentation index
- Redacted web-search path where appropriate
- Developer handover notes
What you provide
- A technical contact
- Repository boundary
- Two VPS (Headscale, AI Gateway)
- Read-only access or sanitized repository bundle (or, for privacy reasons, you can upload it to your AI Gateway later yourself)
- Infrastructure decision: customer server or customer-controlled GPU pod (your Runpod.io secure cloud account)
- Allowed model budget and usage expectations
Not included
- Secret ingestion
- Product database access
- Enterprise SSO
- Unlimited context window or closed AI provider performance
- Model benchmarking
- Full managed operations, infrastructure and security updates unless a support plan for 100 EUR/m is added
- 100 EUR per additional document index, 100 EUR per additional source-code index
- Full managed operations, infrastructure and security updates unless a support plan for 100 EUR/m is added
The starter installation is built to prove value on one real codebase without forcing a broad platform rollout. If it works for your team, we can expand to more repositories, stronger access controls, more models, and managed support.
Jonas, CEO
Built for teams that cannot casually upload private code to public AI tools
Principles
- Customer-controlled infrastructure where practical
- Read-only repository access by default or self-upload after infrastructure handover
- No production database access by default
- No secrets ingestion
- Private network routing for model access
- No routine public AI upload of customer code
- Redaction controls for web-search workflows
- NDA and DPA available where appropriate
- Written handover of assumptions and limitations
No infrastructure setup is automatically secure just because it is private. We design the installation to reduce public exposure and keep customer control explicit, but each deployment still needs appropriate access control, secret hygiene, logging review, and customer security approval.
Starter Installation Topology
Find out if private AI coding makes sense for your team
In a 20-minute fit call, we check your code privacy constraints, current developer workflow, preferred infrastructure path, and whether a starter installation is realistic.
